Many IT Administrators, both on the IBM and Microsoft side, take a reactive approach to IT incident management. Typically, an administrator will receive an alert that notifies them of a current IT issue or shortage in resources. However, often times, that same administrator will not be aware of an issue until they are bombarded with help desk calls and emails from agitated users. According to a recent ITIC survey, the average cost of downtime is more than $100,000 per hour. At this steep price point, the cost of server downtime can add up very quickly.
Server downtime can plague an organization beyond a loss of just revenue. While it’s obvious that employee productivity is greatly impacted, the overall morale and loss of confidence of those employees is the real, and sometimes hidden, cost of IT systems downtime. The organization as a whole can suffer harm to their reputation with current and potential clients when these clients and prospective clients experience performance issues with services. Skilled administrators will tell you, it’s too late to begin troubleshooting after an incident has occurred.
Isn’t time to ditch the outdated reactive approach and implement a proactive approach to incident management? Isn’t time to provide administrators with the right insights to empower them to identify and mitigate issues before they even occur?
Proactive Incident Management With VitalSigns
Predicting issues before they occur? That’s magic you may say. Well, actually it’s simpler than you would imagine. Leveraging the monitoring tool VitalSigns, empowers an both IBM and Microsoft administrators to implement a proactive, predictive approach to their incident management. That’s not magic unless you are an administrator trying to do it without tools.
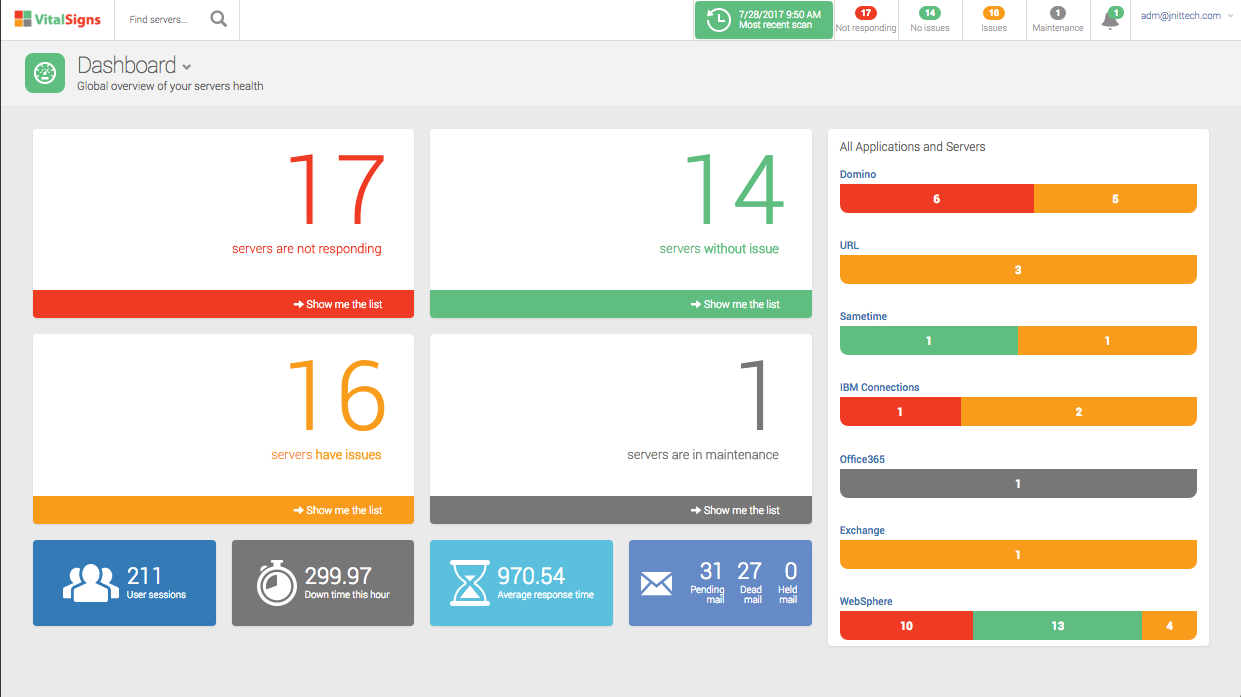
The VitalSigns main dashboard allows IT managers to view the health of both IBM and Microsoft technologies at a glance
End-to-End Monitoring
Proactive incident management starts with data and lots of it. VitalSigns end-to-end monitoring of underlying server components gives administrators complete visibility into their environment with the data they need. This enhanced visibility highlights points of failure, allowing administrators to quickly identify and mitigate issues before end users are severely impacted. Having the knowledge that VitalSigns provides of the current performance at the user endpoint can drastically reduce the time spent troubleshooting.
Identify Performance Baselines
As mentioned above, proactive incident management starts with data. However, it’s what you do with that data that will determine your overall success. With end-to-end monitoring, you now have a plethora of performance metrics for each user endpoint. Overtime, VitalSigns will gather and store these metrics allowing for comparative analysis of environment health at different points in time. Taking it a step further, VitalSigns intelligently identifies performance baselines for every component in the environment. Establishing baselines allows administrators to compare the current health of their system against the desired health metrics.
Configure Alerts Based on Thresholds
Now that you have in-depth visibility into your environment and known performance baselines have been established, it’s time to pull out the crystal ball and see into the future. All magic jokes aside, the immense power of predictive incident management comes from combining performance baselines gained from end-to-end monitoring with real-time alerts. Custom alerts can be configured within VitalSigns to notify administrators when performance or available resources are below the normal baselines. Rather than pushing out alerts minutes before an outage, VitalSigns early identification gives administrations ample time to assess the issue at hand and take action.
Trend Reports
Another important aspect of proactive incident management is being able to learn from your (IT) failures. When an outage does occur, it’s important to look at the health of all the components in the environment at that point in time. Using trend reporting within VitalSigns helps administrators to identify failure patterns and make the necessary changes. With VitalSigns when you see where or how it happened in the past – now you can prevent it in the future. Also use Trend reports to assist with resource allocation by highlighting times with frequent resource constraints or abundances.
Learn more about VitalSigns monitoring and reporting for your technology of choice:
SEE ALSO: Enabling and Disabling Multi-Factor Authentication in Office 365
SEE ALSO: IBM to Invest in Notes Domino 10 and Beyond: What Does This Mean For Us..
No responses yet